字符串编码
Encodings should be known, not divined.
问题描述
在前一篇我们使用 pandoc 的 lua filter 解决了 markdown 转 html 中链接问题,但是在调试代码的过程中发现了一个问题,在不同的 shell 中执行 lua 脚本时,输出中文有时会乱码,有时又不会乱码,搞得有点烦,本篇就针对字符串问题做一个探究,搞清楚乱码的源头以及解决方案。
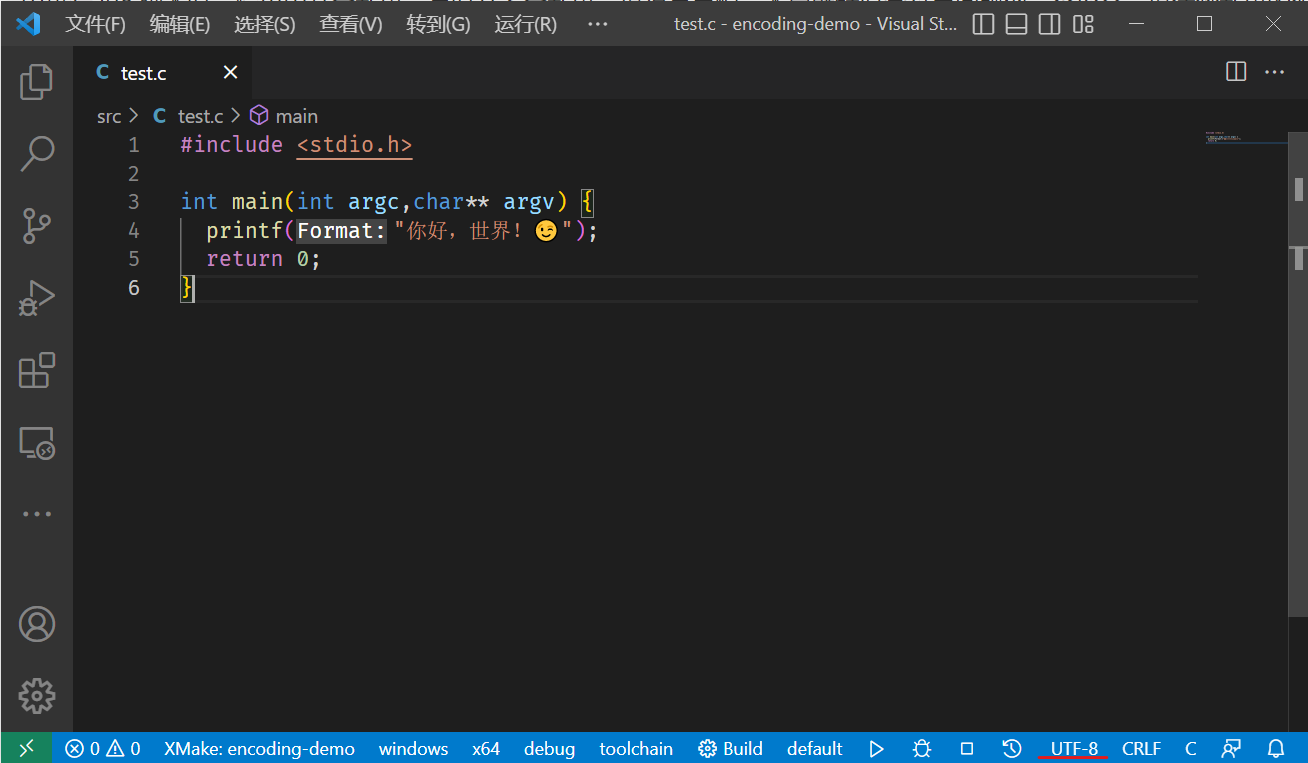
首先看一个简单的示例,下面是一段简单的 C 语言 hello world
1 |
|
文件保存格式为:UTF-8(注意看 vscode 的右下角,写着
UTF-8)
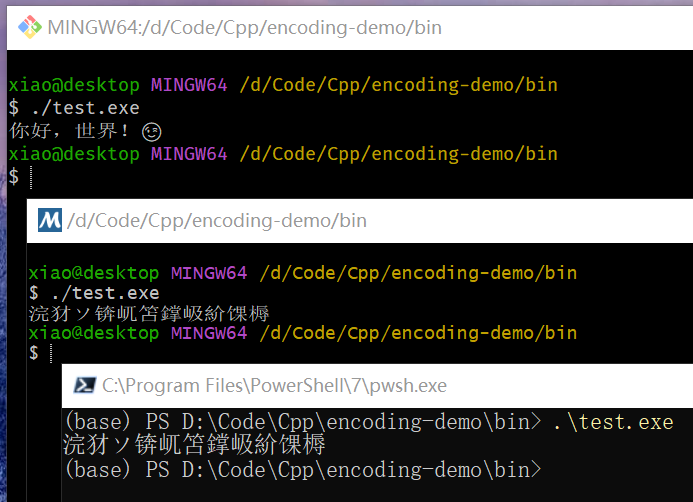
使用 MSVC 编译后,分别在 git bash、msys2、powershell上运行后输出结果如下
注:使用 MSVC 编译 UTF-8 文件时,需要添加
/utf-8参数,否则会使用本机默认编码进行编译,有可能导致编译失败。

可以看到,仅在 git bash 中能正确输出中文,如果我们将编码保存为 GBK,再编译运行
输出结果如下:
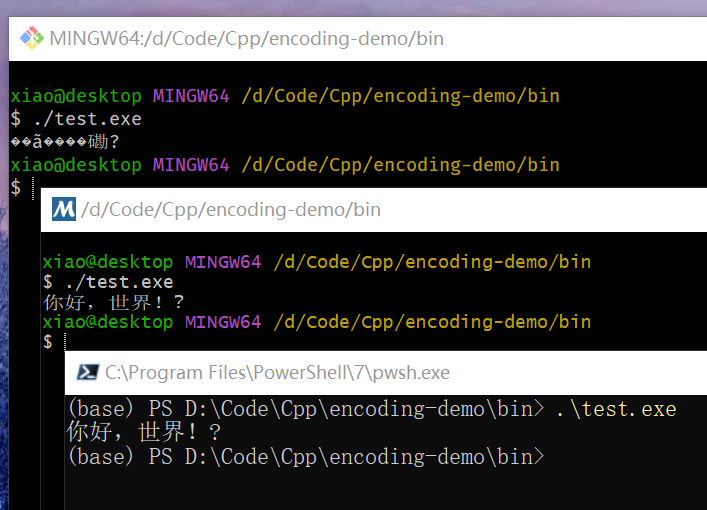
可以看到此时在 Git Bash 中输出乱码了,而在 msys2 和 powershell 中可以正确输出中文了,但是 emoji 的输出还是有问题(变成了问号)
再使用 python 输出上面那句话看看效果
1 | print("你好,世界!😉") |
分别在三个终端中进行测试,输出结果如下
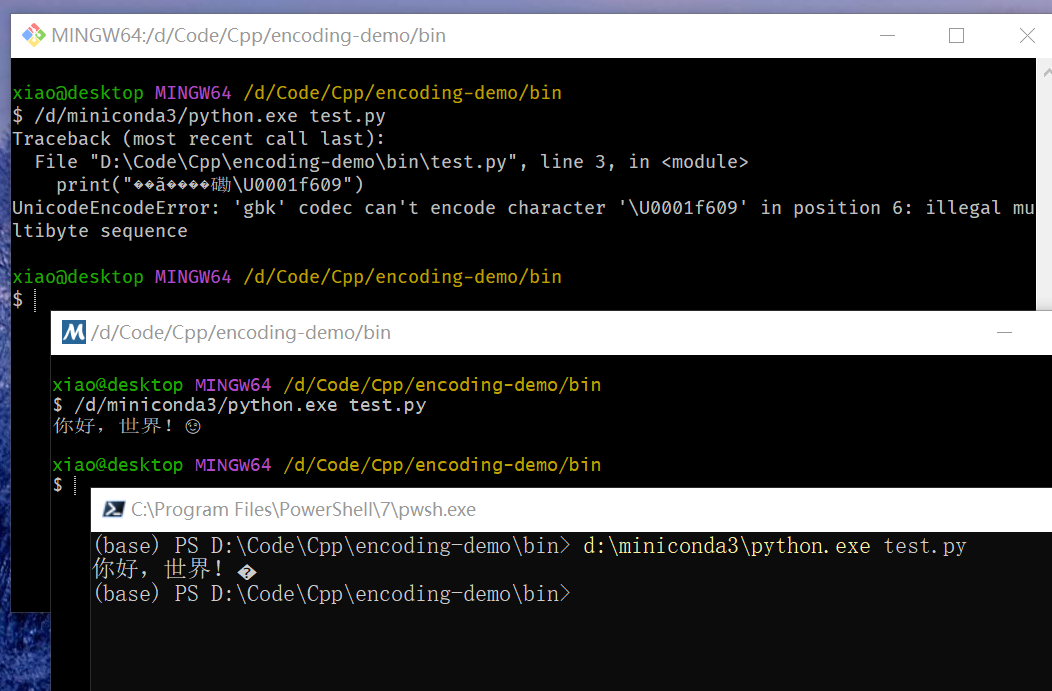
此时 git bash 中直接报错,说 GBK 无法解析 U+1F609
也就是笑脸 😉 ,而在 msys2 和 powershell 中均可以正确输出中文,但是
powershell 中无法输出 emoji 表情,而 msys2 可以正确输出。
这个结果更令人费解了,C 语言和 Python 输出结果不一致,在不同终端下输出也不一样。
编码简史
关于编码的发展过程,下面这篇文章做了很好的介绍
参考这篇文章,我们做一个简单的总结。
ASCII
在计算机中,所有数据都是以二进制形式存储的,我们在屏幕上阅读的文字如 “A”,“你好” 等也需要以二进制形式存储。编码描述的就是我们如何将可阅读的字符存储在计算机中。 ASCII ( /ˈæski/ ) 编码是早期常用的一种编码(现在也很常用,只不过是其他编码兼容该编码罢了)。其包含128个字符,使用 8 位存储(剩下的 128 - 255 部分称为扩展 ASCII 编码,不过并不常用),下图展示了所有的ASCII字符及其对应的编码值(图片来自:http://www.asciicharstable.com/)
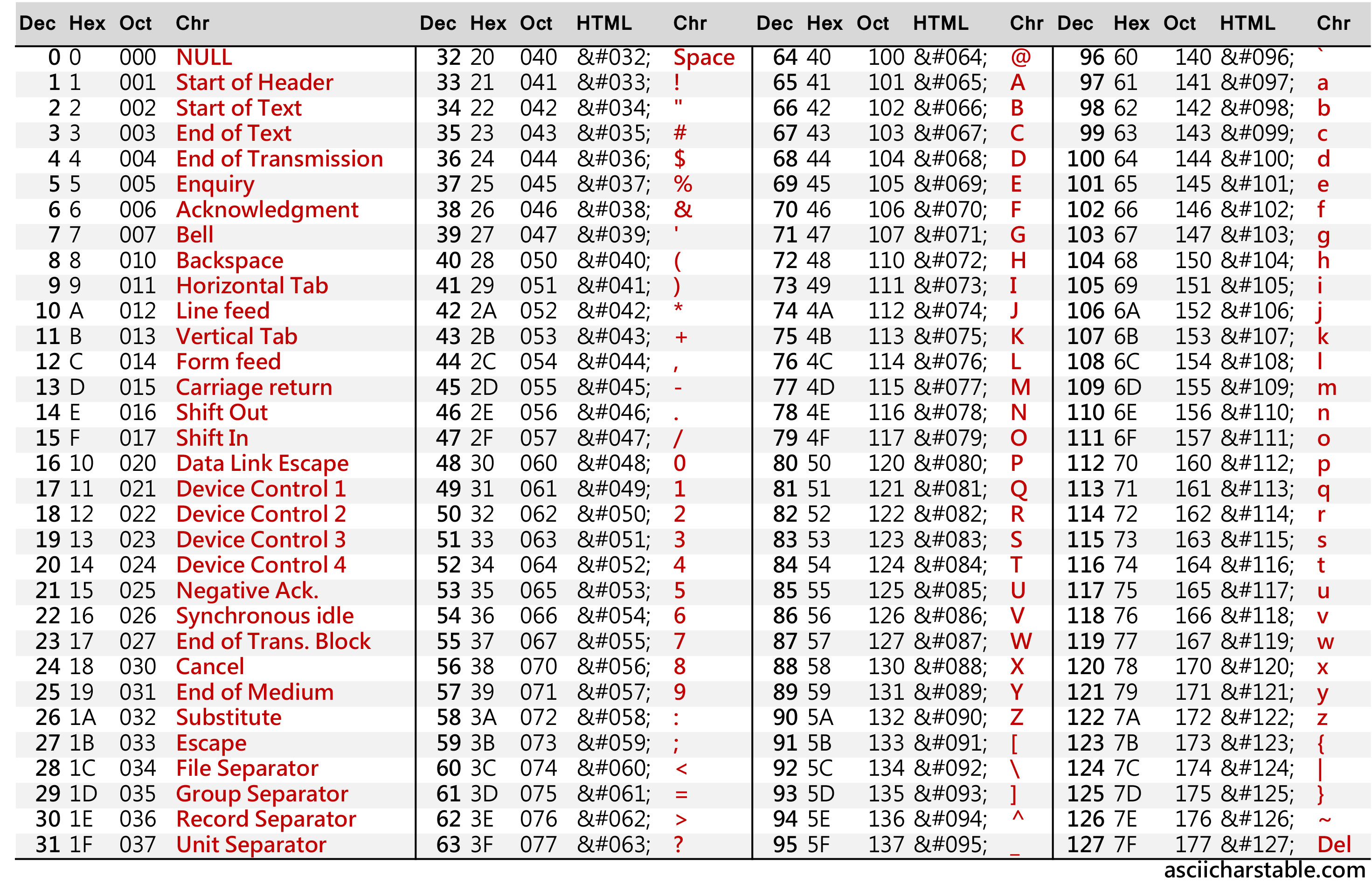
例如大写字母 A 对应的 ASCII 十进制编码就是
65,也即二进制的 0b01000001 和十六进制的
0x41。
从表中可以看到,仅包含大小写字母,而中文、俄语等文字并不包括在内。为了解决这个问题,一些厂家就自定义了一套编码格式,从而支持其他语言的字符显示。但是厂家自定义的编码并不能跨平台,例如在 IBM 上编写的文档就有可能无法在 Mac 上打开,因为他们使用的编码不同。
ANSI
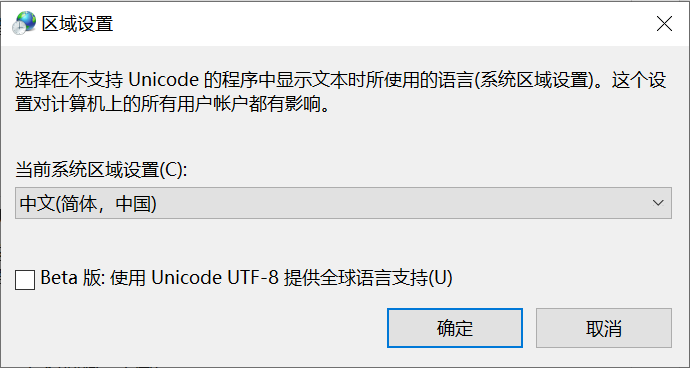
厂家自定义编码太杂乱,为了实现跨平台,后来就统一了编码(车同轨,书同文?),称为 ANSI 编码。ANSI 编码并不将所有的字符都编码到一张表上,其仅确保前 128 个字符(也就是 ASCII 编码部分)是一致的,后面部分的编码由代码页(code page)决定,不同地区使用不同的代码页,从而在不同地区显示不同的文字。目前 Windows 仍然支持的这种编码方式,可以在控制面板的时钟和区域中进行设置。
对于中日韩文而言,其使用的是表意文字(ideograph),可能包含数万个字符,仅使用
8 位显然是无法表示这些字符的。后面就将 ANSI 编码扩展到了两个字节,其中
0x80 至 0xFFFF
部分由代码页来决定编码。中文对应的编码方式有 GB 2312 及其扩展
GBK(Guo jia Biao zhun
Kuo zhan,国家标准扩展)。
注:GBK 和 ANSI 的关系:GBK 属于 ANSI 的一部分,其专门负责对中文进行编码,而其他字母等仍使用 ASCII 编码,例如一段话
Hi, 你好,对应的 GBK ANSI 编码为,其中Hi,仍是单字节编码,而后面的你好则是双字节编码
GBK 实际上是一个定长编码,其描述的所有字符都是双字节,但是此时 ANSI 就是一个变长编码,其既包含单字节字符,也包含双字节字符。
在 Windows 下,可以使用 chcp 命令查看当前控制台使用的
ANSI 代码页(同时也可以使用该命令切换控制台使用的代码页)
1 | (base) PS C:\Users\xiao> chcp |
在程序中可以使用 GetACP()
函数来查询程序中使用的代码页(需要调用 Windows API)
1 |
|
运行结果
1 | (base) PS D:\Code\Cpp\encoding-demo\bin> .\test.exe |
在微软 win32 文档中给出了代码页标识符的相关描述:Code Page Identifiers - Win32 apps | Microsoft Learn

可以看到,本机 Windows 的ANSI代码页编号为 936,对应 GB2312 编码,而后续 GBK 发布后更新了 GBK 部分的字符,因此也常称为 GBK 编码。
采用代码页的方式在单语言场景下足够使用了,但是有时我们可能会浏览其他语言的网站,或接收到其他语言的邮件,我们的系统上就无法显示这些字符了(代码页并不能随便切换)。
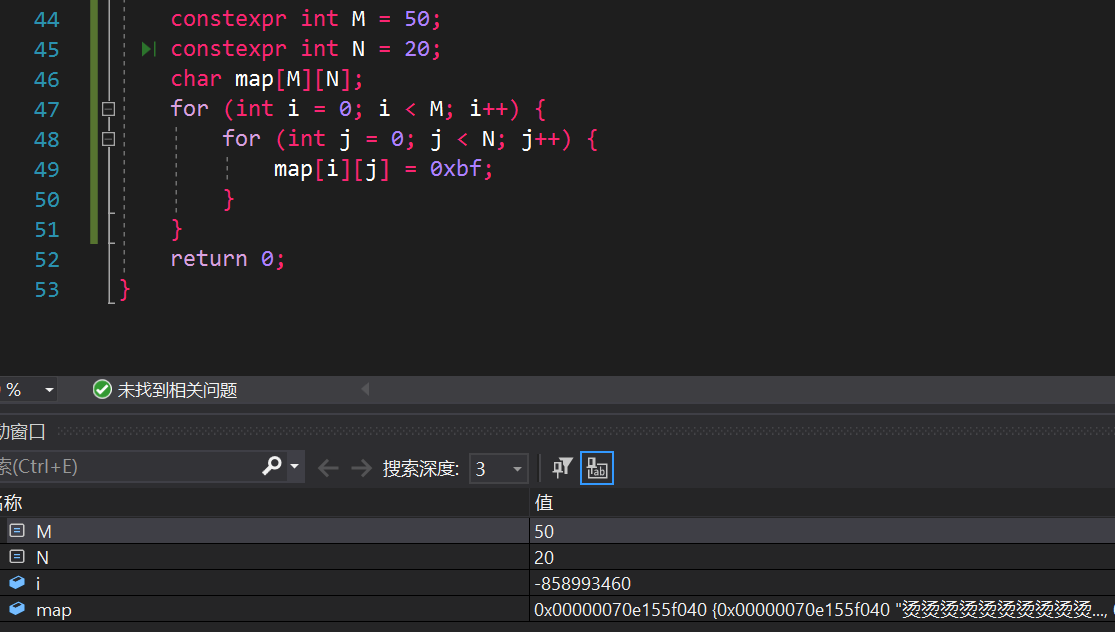
彩蛋:”烫烫烫烫烫烫烫烫...“?
在 GBK 编码中,烫的编码为 [0xCC,0xCC],在 MSVC
的调试模式下,会自动将未初始化的内存设置为
0xCC(字节),用来进行 运行时错误检查。
添加 /RTC1
编译标志即可开启检查功能,我们进行调试时,就会看到如下字样
下面是测试代码
1 | // 此处故意不初始化 |
输出结果就为 烫烫
除了 烫,还有可能出现 屯屯屯屯,因为 MSVC
在调试时会将动态分配的内存值初始化为 0xCD,而
屯 的 GBK 编码刚好是 [0xCD,0xCD]
1 | "烫".encode("gbk") |
Unicode
为了解决在同一系统上的跨语言显示问题,就只能将全部字符编码到一张表上,这种表示方式称为
Unicode,中文称为 统一码,不过一般直接说 Unicode
即可。注意这里我们用的表述是
字符的表示方式,而不是编码方式。Unicode
为每一个字符分配一个 code point(码点),就唯一表示一个字符,例如
你 的 Unicode 码点为 U+4F60,U+
前缀就表示这是一个 Unicode 码点,后面的十六进制就表示具体的代码值。
码点和编码之间并不是一一对应关系,码点只是一个形式化的表示方式(可以理解为字符在字符空间中的一个坐标),其并不关心具体如何在计算机中存储的。UTF (Unicode Transformation Format,Unicode 传输格式) 才是决定具体如何在计算机中存储和传输的,根据使用场景不同,包含以下六类:
- UTF-8
- UTF-8 with BOM
- UTF-16 LE
- UTF-16 BE
- UTF-32 BE
- UTF-32 LE
注:BOM 表示 Byte Order Mark,字节顺序标志,LE 和 BE 分别代表 Little Endian (小端)以及 Big Endian (大端)
大小端与字节顺序
大小端描述的是字节在多字节数据中的存储顺序,例如一个
uint32_t 是 4 个字节,例如
0x1f2f3f4f,其各字节信息如下:
1 | Value(uint32_t): 0x1f2f3f4f |
而其实际在内存中存储按字节顺序可以分为两种存储顺序
按内存地址从低到高,字节顺序从低字节到高字节存储
这种字节排列顺序称为小端,因为低位字节(小值)优先存储
1
2
3
4
5
6
7
8Little Endian Memory View:
+------+---------------+---------------+---------------+---------------+
| addr | 0x1fdd3356050 | 0x1fdd3356051 | 0x1fdd3356052 | 0x1fdd3356053 |
+------+---------------+---------------+---------------+---------------+
| hex | 4f | 3f | 2f | 1f |
+------+---------------+---------------+---------------+---------------+
| bin | 01001111 | 00111111 | 00101111 | 00011111 |
+------+---------------+---------------+---------------+---------------+按内存地址从低到高,字节顺序从高字节到低字节存储
这种字节排列顺序称为大端,因为高位字节(大值)优先存储
1
2
3
4
5
6
7
8Big Endian Memory View:
+------+---------------+---------------+---------------+---------------+
| addr | 0x1fdd3356550 | 0x1fdd3356551 | 0x1fdd3356552 | 0x1fdd3356553 |
+------+---------------+---------------+---------------+---------------+
| hex | 1f | 2f | 3f | 4f |
+------+---------------+---------------+---------------+---------------+
| bin | 00011111 | 00101111 | 00111111 | 01001111 |
+------+---------------+---------------+---------------+---------------+
注:无论是大端还是小端,一个字节中的 bit 的排列顺序永远都是从低位到高位
大端和小端出自 Jonathan Swift 的《格列佛游记》(Gulliver's Travels)一书,其中交战的两个派别无法就应该从哪一端(小端还是大端)打开一个半熟的鸡蛋达成一致。
一下是 Jonathan Swift 在1726年关于大小端之争的历史描述:
“......下面要告诉你的是,Lilliput 和 Blefuscu 这两大强国在过去36个月里一直在苦战。战争开始是由于以下的原因:我们大家都认为,吃鸡蛋前,原始的方法是打破鸡蛋较大的一端,可是当今皇帝的祖父小时候吃鸡蛋,一次按古法打鸡蛋是碰巧将一个手指弄破了,因此他的父亲,当时的皇帝,就下了一道敕令,命令全体臣民吃鸡蛋时打破鸡蛋较小的一端,违令者重罚。老百姓们对这项命令极为反感。历史告诉我们,由此曾发生过六次叛乱,其中一个皇帝送了命,另一个丢了王位。这些叛乱大多都是由 Blefuscu 的国王大臣们煽动起来的。叛乱平息后,流亡的人总是逃到那个帝国去寻救避难。据估计,先后几次有11000人情愿受死也不肯去打破鸡蛋较小的一端。关于这一争端,曾出版过几百本大部著作,不过大端派的书一直是受禁的,法律也规定该派的任何人不得做官。”
(此段译文摘自网上蒋剑锋译的 《格列佛游记》第一卷第4章。)

大小端在日常使用中两者都有可能遇到,但在网络传输中 TCP/IP
规定数据包字节序为大端,如果是小端机器,那么在传输过程中就需要先将小端数据转换成大端数据再进行发送,同时在接受数据时也需要先将数据转换成小端再进行读取(仅针对多字节数据,例如
short,int,double等
),字节序和字符串编码一样,我们在使用前必须提前知道处理的数据字节序情况,否则就会出问题。
UTF-8 & UTF-8 with BOM
前面提到,UTF-8 后面的 8 表示其编码单位是 8 位,即我们可以使用
char 来存储 UTF-8 字符串,但是很明显 8 位存不下所有的
Unicode 字符,那么就使用多个编码单位来表示一个字符。
为了确保我们可以从字节流中准确还原出 Unicode 字符,UTF-8 编码规则如下(RFC3629)
- 确定 Unicode 字符所需要的字节数
- 在首字节中添加长度标识前缀(
110,1110,11110),在剩下字节中添加标识前缀(10) - 对于单字节字符,直接使用 ASCII 编码,对于多字节字符,从低位到高位开始,每次选取 6 位填入编码中(从后向前)
下表展示了 Code 和 UTF-8 编码之间的转换关系
1 | UTF-8 <-> Unicode Conversion |
注:实际上使用 4 个字节的 UTF-8 编码最大可以表示到 U+1FFFFF(21位的 Unicode 字符),且 UTF-8 最多可以使用 6 个字节来表示一个 Unicode 字符,但是为了和 UTF-16 的表示范围一致,其将最大可表示范围限制到了
U+10FFFF(也就是 20 位的 Unicode 字符)
下面来几个转换样例(编码):
A:U+0041
对于在 U+0000 到 U+007F
之间的字符,直接使用 ASCII 码即可
1 | +---------------------+----------+ |
α:U+03B1
1 | +---------------------+----------+----------+ |
你:U+4F60
1 | +---------------------+----------+----------+----------+ |
🧐:U+1F9D0
1 | +---------------------+----------+----------+----------+----------+ |
Unicode 转 UTF-8 代码实现(C++),通过简单的位运算就可以实现了
1 | std::vector<uint8_t> encode_utf8(uint32_t u) { |
对于 UTF-8 字符串的解码,也是类似,我们首先判断当前字节流前缀信息,得出当前字符的字节位数,然后根据这个信息读取后续的字节数据。
1 | bool one_byte = (curr_byte >> 7) == 0x0; |
完整 UTF-8 转 Unicode 代码如下:
1 | std::vector<uint32_t> decode_utf8(const std::string &s) { |
注:对于 UTF-8 的解码,还有很多加速算法,这里就不做过多的介绍了,详细可以参考这篇博客:A Branchless UTF-8 Decoder (nullprogram.com)
最后我们再简单介绍一下 UTF-8 with BOM,从名字上就可以知道,UTF-8 with
BOM 就是在 UTF-8 的基础之上添加了一个 BOM(字节序标志),这个标志的
Unicode code point为 U+FEFF ,表示
”零宽无间断间隔“,仅在传输过程中用来确认字节顺序,打印时不占字宽,(但在控制台打印等宽表格中会计算其长度,导致输出有问题,这一点需要注意)。
1 | UTF-8 encoding of U+00FEFF |
将文件手动保存为 UTF-8 with BOM
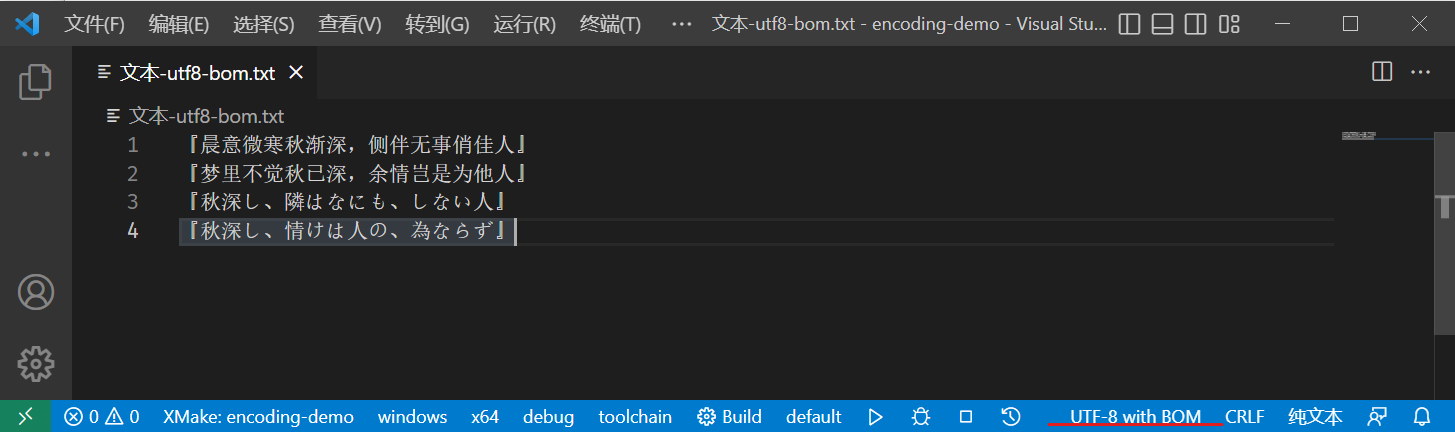
以二进制形式读取文件(rb),我们可以看到文件的前三个字节为固定的
[0xEF,0xBB,0xBF]
1 | +----------------+--------------+-----------------+ |
由于 UTF-8 的编码单位为字节,实际上完全没必要考虑字节顺序的问题,因此并不推荐使用 UTF-8 with BOM ,甚至在某些情况下 UTF-8 with BOM 还会导致代码无法运行(例如 PHP)。
彩蛋:”锟斤拷“ 是怎么来的?
对于编码失败的情况,UTF-8 编码器会直接将其转换成 U+FFFD
,显示为 �,其对应的 UTF-8 编码如下:
1 | UTF-8 encoding of U+00FFFD |
即
[0xEF,0xBF,0xBD],在编码错误的情况下,就可能会连着出现,也就是
1 | [...,0xEF,0xBF,0xBD,0xEF,0xBF,0xBD,...] |
由于 GBK
编码是双字节编码,其会将其解析为三个汉字,而这三个字就是
锟斤拷
1 | b'\xef\xbf\xbd\xef\xbf\xbd'.decode('gbk') |
在中文环境下,出现 锟斤拷
就基本上就表示我们将一个原本是正常编码的文件采用 UTF-8
编码打开并以 UTF-8 保存,由于 UTF-8
编码无法对文件中字符进行编码,就全部替换成了
�,此时我们再通过 GBK 打开时就会出现满屏的
锟斤拷
了,而且这种错误是不可逆的,因为无法编码的字符已经被替换成了
�,我们再也无法找回之前的编码了。
下面给出了一个具体示例:
文件初始内容:

我们原本的文件是 GBK 编码的,我们将窗口关闭,再打开。由于 VS Code 并不知道文件的编码,便默认使用 UTF-8 编码打开,内容如下:
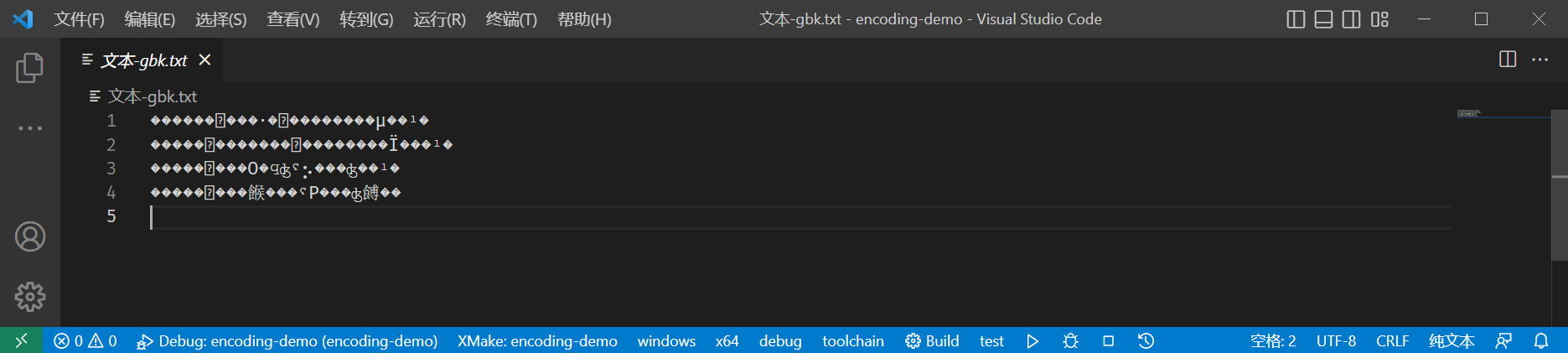
如果此时我们手贱,将文件保存的话(Ctrl +
S),文件就会以 UTF-8 编码保存,而其中 �
就会直接写入到文件中。
假如我们又看到了文件名中的
文本-gbk,知道文件的正确编码为 GBK,再次使用 GBK
编码打开时,文件内容如下: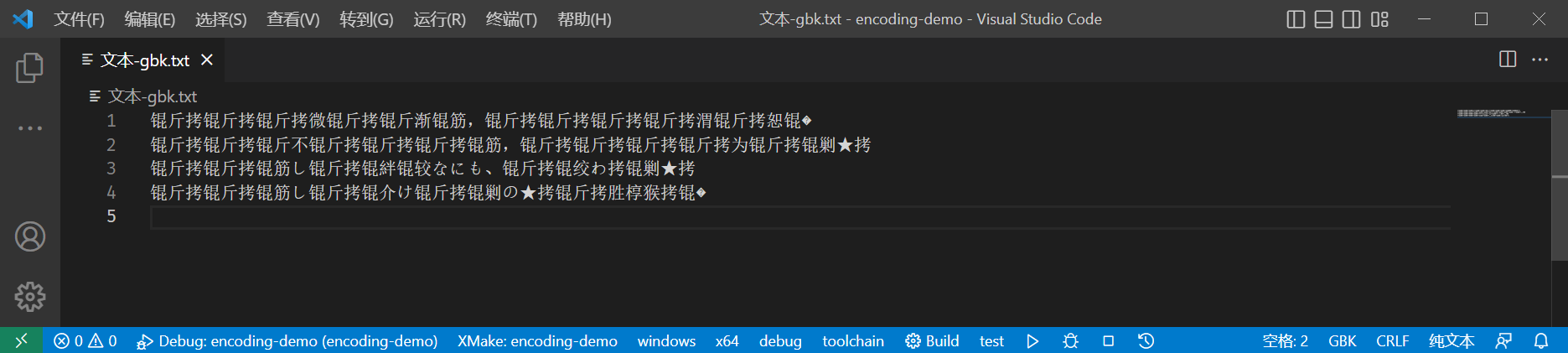
我们永远也不知道文件里写了什么了!😭
“白色相簿”什么的,已经无所谓了。
因为已经不再有歌,值得去唱了。
传达不了的恋情,已经不需要了。
因为已经不再有人,值得去爱了。
血的教训告诉我们:当打开不知道编码的文件时,千万不要手贱按下保存,保存后很有可能无法还原了!
UTF-16 & UTF-32
UTF-16 的编码单位为 16 位,即 2 字节,而 UTF-32 的编码单位为 32 位,4字节。
注:编码单位(code unit)是编码中每个字符编码的基本元素,对于定长编码中,编码单位大小就等于字符大小,例如 GBK 中编码单位为 2 字节,其可表示的所有字符都是 2 字节;对于变长编码,一个字符的编码可以由多个编码单位进行表示。
由于 UTF-16 和 UTF-32
的编码单位为多字节,必定要考虑字节顺序问题。我们可以手动指定字节顺序(和
UTF-8 with BOM 类似,在文件开头添加 U+FEFF
来自动判断编码),也可以直接使用 LE
后缀或BE后缀的编码来表示,例如 UTF-16LE 和 UTF-16BE。
在 UTF-16 编码中,一个字符由1个或2个16位整数表示,最大可表示字符为
U+10FFFF,参考 UTF-16
规范(RFC2781),其编码和解码规则如下:
- 对于
U+0000 ~ U+FFFF的字符,其直接使用1个16位整数表示即可,且值等于 Unicode Code Point 值。 - 对于
U+010000 ~ U+10FFFF的字符,使用2个16位整数表示(称为 surrogate pair,代理对,意为16位整数对表示一个字符),每个部分存储 Unicode Code Point 的10 位(需要进行特殊处理),再在前面添加前缀(6 位),第一个前缀为110110,第二个前缀为110111 - 对于
> U+10FFFF的字符无法使用 UTF-16 编码表示(目前并不存在)
为了保证 UTF-16 解码的唯一性,对于
U+D800 ~ U+DFFF的 Unicode 字符不做编码。
同样,下面给出了一个转换示例
🧐:U+1F9D0
首先减去
0x10000,确保U'的范围在0xFFFFF之间(最多支持 20 位)1
2U' = U - 0x10000
= 0xf9d0分别取出
U'的 前10位和后10位,填充到两个16位整数中1
2
3
4w0 = (U' >> 10) & 0x3ff
= 0b0000111110
w1 = U' & 0x3ff
= 0b0111010000最后添加6位的前缀
1
2
3
4
5
6w0 = w0 | 0xd800
= 0b1101100000111110
= 0xd83e
w1 = w1 | 0xdc00
= 0b1101110111010000
= 0xddd0
最终得到 🧐 的 UTF-16 编码为
[0xd83e,0xddd0]
- UTF-16LE:
b'\x3e\xd8\xd0\xdd' - UTF-16BE:
b'\xd8\x3e\xdd\xd0'
代码写起来就十分简单了,将上面的过程翻译成 C++ 位运算即可
1 | std::vector<uint16_t> encode_utf16(uint32_t u) { |
对于解码也是一样,不过我们需要验证一下 surrogate 的有效性(必须成对存在)
1 | std::vector<uint32_t> decode_utf16(const std::vector<uint16_t> &s) { |
注:UTF-16、UTF-16LE、UTF-16BE 的区别:
- UTF-16 类似于 UTF-8 with BOM,在文件开头添加
U+FEFF标记,用来标识存储内容的字节顺序- 而 UTF-16LE 和 UTF-16BE则是在编码时就约定好字节顺序,不需要通过 BOM 来确定。
对于 UTF-32、UTF-32LE、UTF-32BE 也是类似,和 UTF-8 with BOM 类似,一般直接使用 LE 或 BE 版本即可,最好不要在文件开头添加 BOM(有可能影响文件解析)
而对于 UTF-32 编码,就简单很多了,目前最大的 Unicode 字符也就到
U+10FFFF,使用 32 位来表示完全足够了(即 Unicode code point
就是 UTF-32 编码值)。但是代价也很明显,存储代价太大了,对于纯 ASCII
的代码,需要 4 倍的存储空间。而在 Python 中就采用了
Latin-1(ASCII)、UTF-16 和 UTF-32
的混合表示方式(代价是性能,但是其字符串操作上十分便捷)。
Unicode in C++
目前 Windows 并不支持 UTF-8(使用的 UTF-16),如果我们编写了一段 c++
程序输出 UTF-8
字符串,我们会看到乱码的结果。除此之外,对于文件的读写、命令行参数的传递也会出现同样的问题。如果我们想编写跨平台应用程序,最好保证使用的所有字符串都是
UTF-8。通过 Boost.Nowide
库可以实现这个转换。(单纯输出乱码的话可以使用 fmt::print
来解决乱码问题)
使用时我们需要确保在程序中使用的 char* 和
std::string 都是 UTF-8
编码的,进行文件I/O、解析命令行命令以及 stdout、stdin、stderr
时统一使用nowide库进行操作,就基本可以屏蔽掉大部分的坑。
对于命令行命令的解析,有一点小坑,我们需要手动链接
shell32.dll ,这个在 Windows SDK
中自带,只需要链接上即可。
1 |
|
对应的 xmake
1 | target("nw") |
输出结果
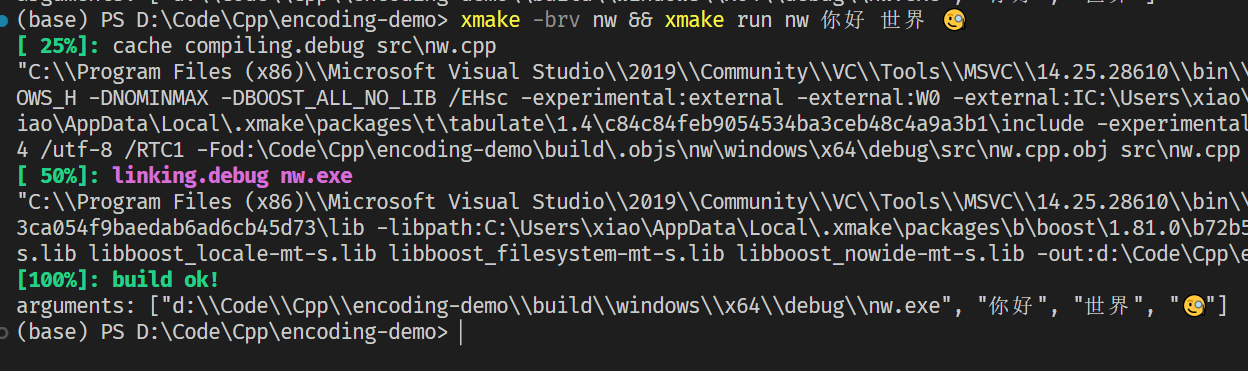
此处链接 shell32.dll 十分关键,如果没有就会报错
LNK2019:无法解析的外部符号 __imp_CommandLineToArgvW

这个函数实际上就是 Windows 提供的命令行参数编码转换函数,具体可以参考:CommandLineToArgvW function (shellapi.h) - Win32 apps | Microsoft Learn
还有另外一种解决方案,就是开启 UTF-8 实验性功能,这样 Windows 强制所有编码都是 UTF-8,就是对一些老应用不友好,特别是之前编译的中文应用,因为其使用的可能是 GBK 编码。
将其勾上然后重启电脑就可以了,这样我们直接通过 std::cout
以及 std::fstream
打开文件时就不会乱码了,但是无法确保其他人也这么做,所以还是老老实实使用
Nowide 库比较靠谱。
参考
- The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!) – Joel on Software
- UTF-8 遍地开花 (utf8everywhere.org)
- Boost.Nowide: Boost.Nowide - 1.81.0
- GetACP function (winnls.h) - Win32 apps | Microsoft Learn
- Code Pages - Win32 apps | Microsoft Learn
- Code Page Identifiers - Win32 apps | Microsoft Learn
- visual c++ - Getting error LNK2019: unresolved external symbol when compiling SDL2 code in Windows using MSVC - Stack Overflow
- c# - What does "Beta: Use Unicode UTF-8 for worldwide language support" actually do? - Stack Overflow