投影变换矩阵
Hello Projection
所谓投影,就是 将高维空间中的对象通过某种方式映射到低维空间,或者映射到另一个空间中。如下图所示(图片来自网络)。
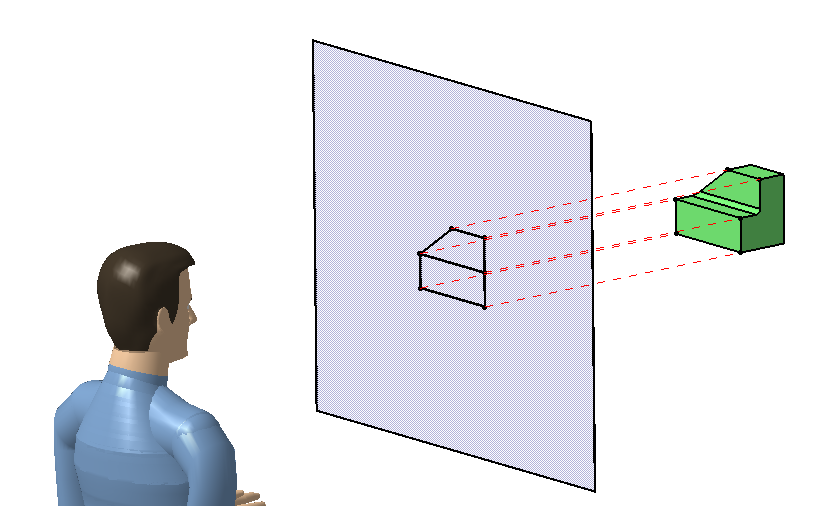
当我们在二维平面上展示三维物体时,看到的其实就是三维物体在二维空间中的一个投影,而这个从三维到二维的转换过程就是投影变换。
如果投影过程可以表示成线性变换,就可以用一个矩阵来描述它,如下式所示,其中 \(M_\text{projection}\) 就称为投影变换矩阵。 \[ P^{\prime} = M_{\text{projection}} \cdot P \]
正交投影
正交投影的一个特点是不会改变直线之间的平行关系,因此待投影区域一定是一个长方体。我们可以用六个参数 \((l,r,t,b,n,f)\) 来描述这个长方体,分别对应 left、right、top、bottom、near、far 六个平面的位置。
它们满足 \(l<r\)、\(b<t\)、\(f<n\)。这里之所以有 \(f<n\),是因为我们假设观察方向沿着 z 轴负方向。
投影的目标是把这个长方体的中心移动到原点,并进一步转换成单位正方体,也就是 NDC(normalized device coordinates)。
因此,正交投影矩阵可以拆成两个步骤:平移变换和缩放变换。
标准正方体的两个对角点可以记为 \((l,b,n)=(-1,-1,-1)\) 和 \((r,t,f)=(1,1,1)\)。此时 \(n<f\),更符合我们的日常直觉,也就是从 z 轴正方向看去时,越远的点 z 坐标越大。
而实际待投影长方体的长、宽、高以及中心位置分别为: \[ \begin{align*} &(r-l,t-b,n-f) \\ &(\frac{r+l}{2},\frac{t+b}{2},\frac{n+f}{2}) \end{align*} \] 因此我们首先要把它的中心移动到 \((0,0,0)\),对应的平移矩阵为: \[ T(\hat{t}) = \left[ \begin{matrix} 1 & 0 & 0 & -\frac{r+l}{2} \\ 0 & 1 & 0 & -\frac{t+b}{2} \\ 0 & 0 & 1 & -\frac{n+f}{2} \\ 0 & 0 & 0 & 1 \end{matrix} \right] \] 然后再通过缩放把这个长方体转换成标准正方体即可,其中标准正方体的边长为 2: \[ S(\hat{s}) = \left[ \begin{matrix} \frac{r-l}{2} & 0 & 0 & 0 \\ 0 & \frac{t-b}{2} & 0 & 0 \\ 0 & 0 & \frac{n-f}{2} & 0 \\ 0 & 0 & 0 & 1 \end{matrix} \right] \] 经过这两步之后,得到的标准正方体在 z 方向上的前后关系仍然是 \(n>f\),也就是 \(n=1\)、\(f=-1\),这和我们平时的直觉不太一致。因此可以再对 z 坐标做一次镜像变换,把它转换成 \(n=-1\)、\(f=1\),也就是在 z 轴上取反: \[ M_z= \left[ \begin{matrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & -1 & 0 \\ 0 & 0 & 0 & 1 \end{matrix} \right] \] 最后把这三个操作组合起来,就可以得到最终的正交投影矩阵: \[ \begin{align*} P_O = M_zS(\hat{s})T(\hat{t}) & = \left[ \begin{matrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & -1 & 0 \\ 0 & 0 & 0 & 1 \end{matrix} \right] \left[ \begin{matrix} \frac{2}{r-l} & 0 & 0 & 0 \\ 0 & \frac{2}{t-b} & 0 & 0 \\ 0 & 0 & \frac{2}{n-f} & 0 \\ 0 & 0 & 0 & 1 \end{matrix} \right] \left[ \begin{matrix} 1 & 0 & 0 & -\frac{r+l}{2} \\ 0 & 1 & 0 & -\frac{t+b}{2} \\ 0 & 0 & 1 & -\frac{n+f}{2} \\ 0 & 0 & 0 & 1 \end{matrix} \right] \\ & = \left[ \begin{matrix} \frac{2}{r-l} & 0 & 0 & -\frac{r+l}{r-l} \\ 0 & \frac{2}{t-b} & 0 & -\frac{t+b}{t-b} \\ 0 & 0 & \frac{2}{f-n} & -\frac{n+f}{f-n} \\ 0 & 0 & 0 & 1 \end{matrix} \right] \end{align*} \]
上面的写法稍微有些繁琐,因为这里默认假设视角从原点看向 z 轴负方向,所以 \(n\) 和 \(f\) 都是小于 0 的,并且满足 \(f<n\)。为了保证长、宽、高都是正值,缩放长度中就会出现 \(n-f\)。
实际上,如果目标只是让 \(n\) 在 NDC 中对应到 \(z=-1\),让 \(f\) 对应到 \(z=1\),那么直接使用 \(f-n\) 也可以。它的几何意义就是把 \([n,f]\) 区间直接缩放到 \([-1,1]\) 区间,两种写法本质上是等价的,只不过后一种把方向翻转的过程隐含进去了。
透视投影
和正交投影相比,透视投影具有近大远小的效果。平行线在透视投影中不再保持平行,而是会相交于一点,因此更能体现深度变化,看起来也更有立体感。
因此,待投影区域不再是一个长方体,而是一个视锥体(frustum)。为了把这个锥体最终投影到二维平面上,我们可以先把视锥体转换成长方体,再继续套用正交投影。
下面展示了视锥体的示意图:
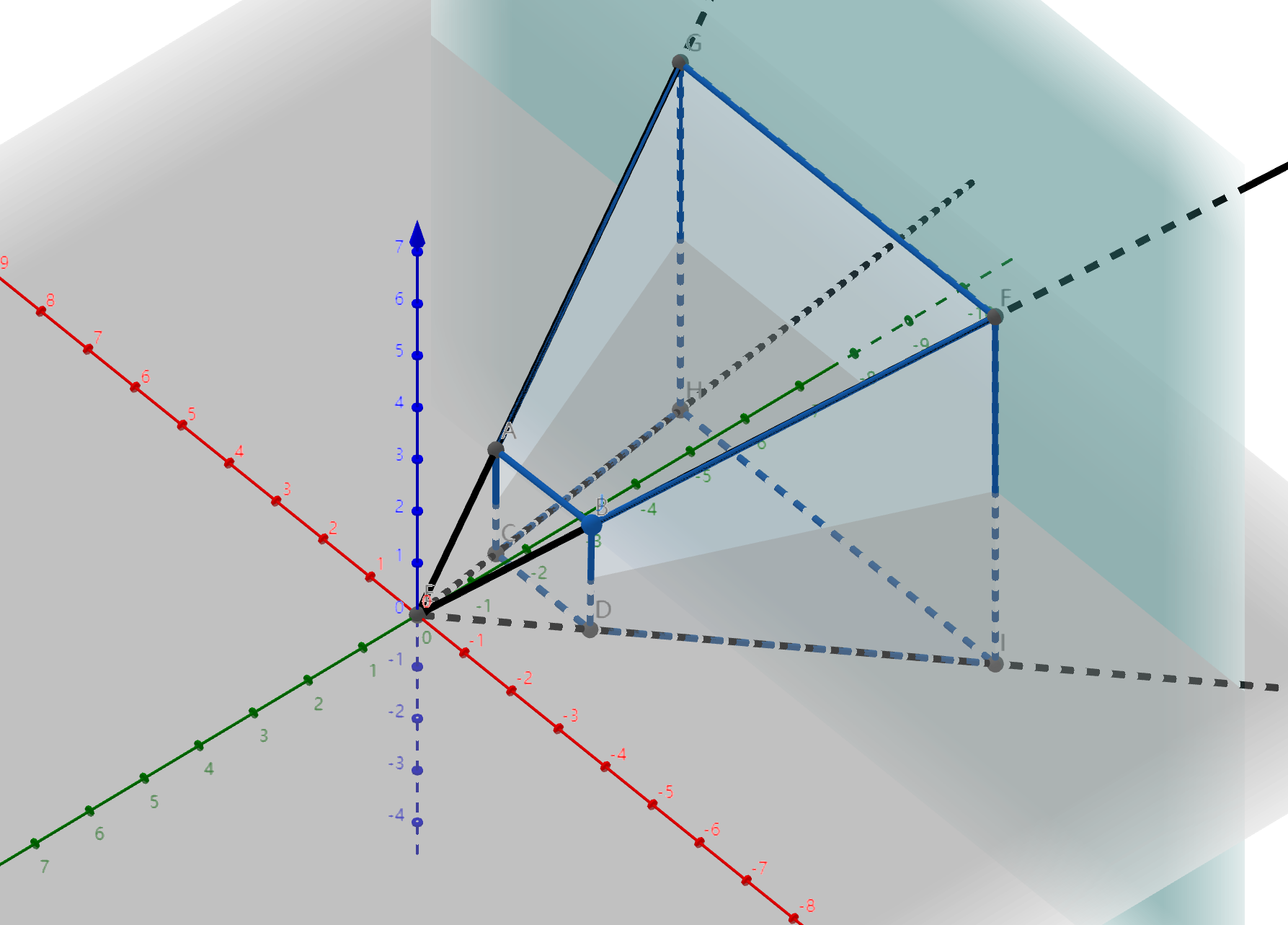
下面简单推导一下如何把视锥体转换成长方体。从图中可以观察到 3 个性质:
视锥体中任意一点在 n 面上的投影,都是“过原点和该点的连线”与 n 面的交点,因此满足相似三角形性质,如下图所示:
![]()
锥体前面,也就是 n 面上的点,投影前后坐标不发生变化。
锥体后面,也就是 f 面的中心位置不会变化,即 \((0,0,f)\) 投影后仍然是 \((0,0,f)\)。
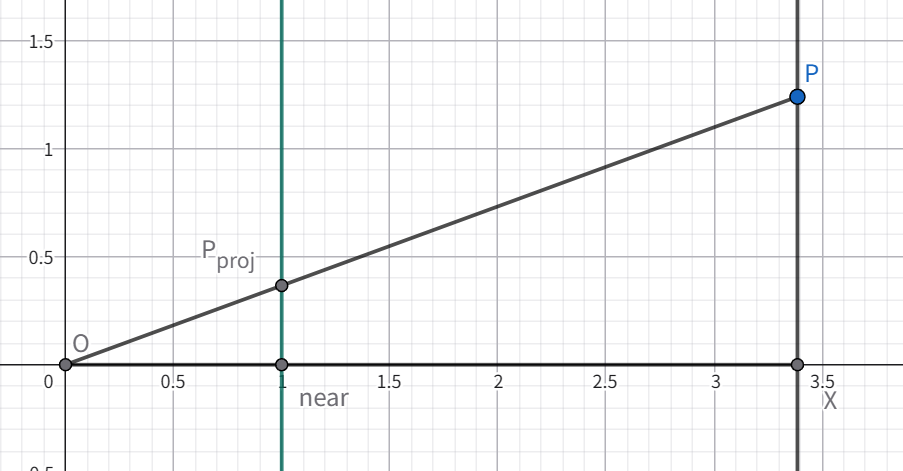
首先根据观察 1:相似三角形,有如下关系: \[ \begin{align*} \frac{x}{z} = \frac{x_{\text{proj}}}{n} & \quad x_{\text{proj}} = \frac{n}{z} \cdot x \\ \frac{y}{z} = \frac{y_{\text{proj}}}{n} & \quad y_{\text{proj}} = \frac{n}{z} \cdot y\\ \end{align*} \] 这说明投影区域内任意一点 \((x,y,z,1)\) 在 n 面上的投影可以写成 \((\frac{n}{z}x,\frac{n}{z}y,?,1)\)。如果同时乘上 \(z\),就可以写成齐次形式 \((nx,ny,?,z)\)。这里投影后的 \(z\) 值暂时未知,因为投影到二维 \(xy\) 平面时只需要关心 \(x\) 和 \(y\),而 \(z\) 的具体表达式还没有确定。于是我们可以先把变换矩阵的第 1、2、4 行写出来: \[ M_\text{perspective} = \left[ \begin{matrix} n & 0 & 0 & 0 \\ 0 & n & 0 & 0 \\ A & B & C & D \\ 0 & 0 & 1 & 0 \end{matrix} \right] \] 接下来只剩下矩阵的第三行未知,我们可以利用前两个性质来确定它:
由观察 2:n 面上任意一点的坐标不会变化,因此有: \[ \begin{align*} P_1^{\prime} & = (x,y,n,1) \\ & = M_\text{perspective} P_1 \\ & = (nx,ny,Ax+By+Cn+D,n) \\ & = (nx,ny,n^2,n) \end{align*} \] 于是可以得到: \[ Ax + By + Cn + D = n^2 \] 又由于这个等式对投影区域内任意一点都成立,因此 \(A\) 和 \(B\) 一定为 0: \[ \begin{cases} A = 0 \\ B = 0 \\ Cn + D = n^2 \end{cases} \] 再由观察 3:f 面中心坐标不变,则有: \[ \begin{align*} P_2^{\prime} & = (0,0,f,1) \\ & = M_\text{perspective}P_2 \\ & = (0,0,Cf+D,f)\\ & = (0,0,f^2,f) \end{align*} \] 即 \[ Cf + D = f^2 \] 联立两式可得: \[ \begin{cases} Cn+D = n^2 \\ Cf+D = f^2 \end{cases} \] 从而可以解出 \(C\) 和 \(D\): \[ \left\{ \begin{array}{ll} C = n+f\\ D = -nf \end{array} \right. \] 于是完整的透视变换矩阵为: \[ \left[ \begin{matrix} n & 0 & 0 & 0 \\ 0 & n & 0 & 0 \\ 0 & 0 & n+f & -nf \\ 0 & 0 & 1 & 0 \end{matrix} \right] \] 经过这个变换之后,待投影区域就已经变成一个长方体了。此时只需要再施加一次正交投影,就可以把它转换成标准立方体: \[ P_P = P_OM_\text{perspective} = \left[ \begin{matrix} \frac{2n}{r-l} & 0 & 0 & 0 \\ 0 & \frac{2n}{t-b} & 0 & 0 \\ 0 & 0 & \frac{f+n}{f-n} & -\frac{2nf}{f-n} \\ 0 & 0 & 1 & 0 \end{matrix} \right] \]
此时矩阵参数仍然比较多,一共有 6 个。我们可以进一步假设待投影区域关于 z 轴对称,并且观察点位于原点。这样一来,\(r-l\) 和 \(t-b\) 就可以用 aspect 和 fov 两个参数来替代: \[ \begin{align} \text{w} & = r - l \\ \text{h} & = t - b \\ \text{aspect} & = \frac{\text{w}}{\text{h}} = \frac{r-l}{t-b} \\ ext{fov} & = 2 \arctan (\frac{\text{h}}{2n}) \\ c &= \frac{2n}{t-b} = \frac{1}{\tan(\frac{\text{fov}}{2})} \\ a &= \text{aspect} \end{align} \] 这样一来,只需要 aspect、fov、near、far 这 4 个参数,就可以写出最终的透视投影矩阵:
\[ P_P = P_OM_\text{perspective} = \left[ \begin{matrix} \frac{c}{a} & 0 & 0 & 0 \\ 0 & c & 0 & 0 \\ 0 & 0 & \frac{f+n}{f-n} & -\frac{2nf}{f-n} \\ 0 & 0 & 1 & 0 \end{matrix} \right] \]
通过矩阵计算后得到的是齐次坐标,再执行透视除法,就能得到投影后的三维 NDC 坐标: \[ \begin{pmatrix} x_\text{ndc}\\ y_\text{ndc}\\ z_\text{ndc} \end{pmatrix}= \begin{pmatrix} {\tfrac {x_{c}}{w_{c}}}\\ {\tfrac {y_{c}}{w_{c}}}\\ {\tfrac {z_{c}}{w_{c}}} \end{pmatrix} \]
此时 \(z_\text{ndc}\) 的取值范围为 \([-1,1]\),而原始 z 的取值范围为 \([n,f]\)。如果还需要得到 z-buffer 中实际存储的值,则要再做一次线性变换。这个过程通常会在 viewport 变换中自动完成,也就是把 \([-1,1]\) 区间映射到 \([0,1]\): \[ z_{\text{buffer}} = 0.5 * (z_{\text{ndc}} + 1) \]
深度转换
在 shader 中,经常需要在 \(z_{\text{ndc}}\) 和原始坐标 \(z\) 之间来回转换。根据上面的矩阵公式,可以直接推导出它们之间的关系: \[ \begin{align} z_\text{ndc} & = \left(\frac{f+n}{f-n} \cdot z - \frac{2nf}{f-n}\right) \cdot \frac{1}{z} \\ & = \frac{f+n}{f-n} - \frac{2nf}{(f-n) \cdot z} \\ z & = \frac{2nf}{f+n - (f-n)\cdot z_\text{ndc}} \end{align} \]
如果需要获得归一化的线性深度,还需要进一步把 \(z\) 归一化到 \([0,1]\) 区间内,即: \[ z_{\text{depth01}} = \frac{z-n}{f-n} \] 在实际情况下,\(n\) 往往是一个很小的值,很多时候可以近似忽略,因此上式可以进一步简化为 \(\tilde{z}_{\text{depth01}} = z / f\)。这样计算公式就可以写成: \[ \tilde{z}_\text{depth01} = \frac{2n}{f+n-(f-n) \cdot z_{ndc}} \] 根据 \(z_{\text{buffer}}\)、\(z_\text{depth01}\) 和 \(z\) 之间的关系,可以画出如下曲线(\(n=1\),\(f=10\)):

其中:
- 灰色曲线代表 \(z_\text{buffer}\)
- 绿色直线代表 \(z_{\text{depth01}}\)
- 蓝色和红色竖线代表 \(n\) 和 \(f\)
- \(x\) 轴对应原始的 \(z\)
从图中可以看出,\(z\) 本身是线性增加的,而 \(z_\text{ndc}\) 并不是。随着 \(z\) 逐渐增大,深度之间的差异会越来越小。这也符合近大远小的特性,因为越靠近相机的物体,对深度精度的要求越高。
当我们需要进行深度比例的计算时,就需要使用线性深度值,此时可以将 \(z_\text{ndc}\) 转换为 \(z_\text{depth01}\) 后进行后续计算。