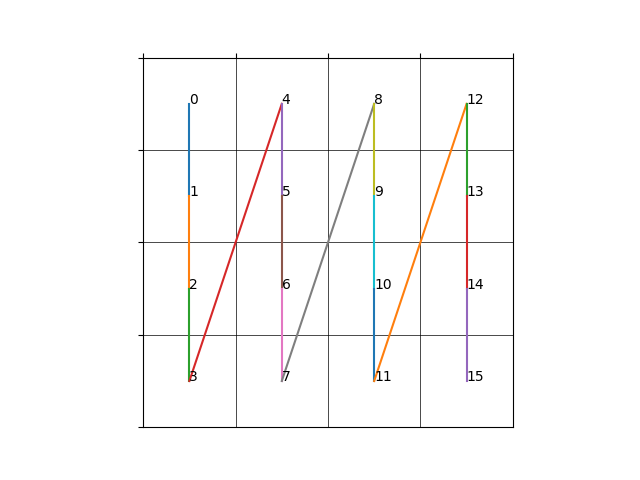
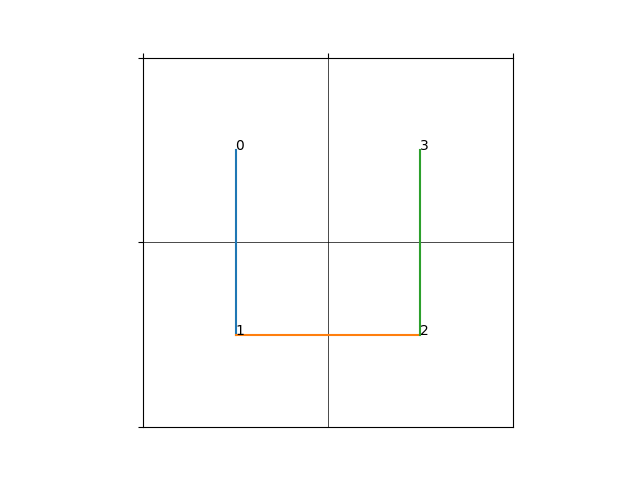
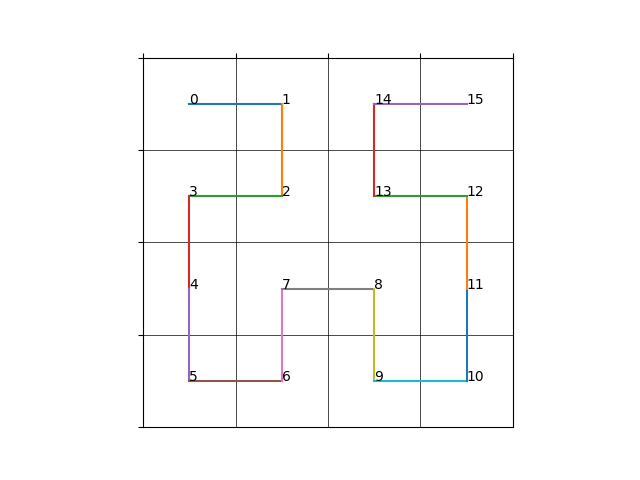
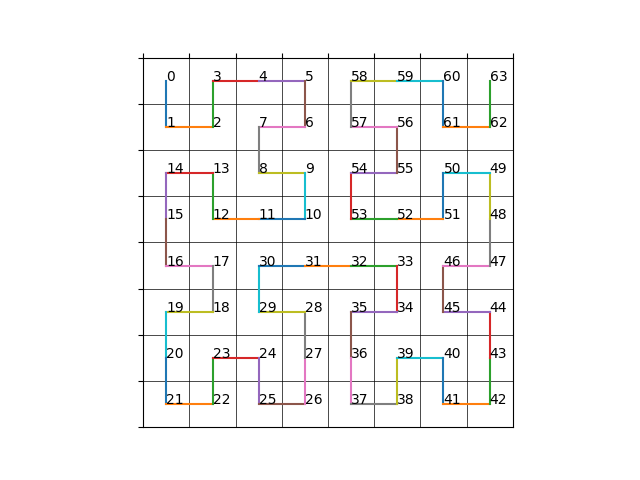
一种最为简单的存储方式就是逐行地或逐列地存储二维数据,对于一个指定大小的二维方块(\(w\times h\)),从0开始的坐标\((x,y)\) 对应的一维地址为(一行包含\(w\)个元素) \[
v = x \times w + y
\] 同理,将一维坐标\((v)\)转换二维方块坐标也很简单,只需要对行/列进行整除和取余操作即可
\[
\begin{align}
x &= \lfloor v / w \rfloor \\
y &= v - x \times w
\end{align}
\]
上面这种方式在一般情况下足够使用,但是对于纹理/体素等数据的读取时,通常会利用到二维/三维坐标的局部性(即当我们访问坐标\((x,y)\)时,我们有很大概率将访问该坐标周围的坐标),而使用线性存储方式则会丢失这种局部性。
import numpy as np import matplotlib.pyplot as plt from matplotlib.animation import FuncAnimation
# 线性遍历:按行遍历 deflinear_traversal(n): order = [] for i inrange(n): for j inrange(n): order.append((i, j)) return order
# Morton编码 defmorton_encode(x, y): z = 0 i = 0 while x > 0or y > 0: z |= (x & 1) << (2 * i) z |= (y & 1) << (2 * i + 1) x >>= 1 y >>= 1 i += 1 return z
# Morton遍历:按Morton编码排序 defmorton_traversal(n): points = [(i, j) for i inrange(n) for j inrange(n)] points.sort(key=lambda p: morton_encode(p[0], p[1])) return points
# Hilbert编码(简化版,对于2^n网格) defhilbert_encode(x, y, n): d = 0 s = n // 2 while s > 0: rx = 1if (x & s) > 0else0 ry = 1if (y & s) > 0else0 d += s * s * ((3 * rx) ^ ry) if ry == 0: if rx == 1: x = n - 1 - x y = n - 1 - y x, y = y, x s //= 2 return d
# Hilbert遍历:按Hilbert编码排序 defhilbert_traversal(n): points = [(i, j) for i inrange(n) for j inrange(n)] points.sort(key=lambda p: hilbert_encode(p[0], p[1], n)) return points
# 可视化函数 defvisualize_traversal(order, title): fig, ax = plt.subplots() ax.set_xlim(-0.5, 3.5) ax.set_ylim(-0.5, 3.5) ax.set_aspect('equal') ax.set_title(title) ax.grid(True) # 绘制网格 for i inrange(4): for j inrange(4): ax.add_patch(plt.Rectangle((i-0.5, j-0.5), 1, 1, fill=False)) # 动画:逐步显示遍历顺序 points = [] defupdate(frame): if frame < len(order): x, y = order[frame] points.append(ax.plot(x, y, 'ro', markersize=10)[0]) return points ani = FuncAnimation(fig, update, frames=len(order)+1, interval=500, repeat=False) plt.show()
// 线性编码:v = x * w + y uint32_tlinear_encode(uint32_t x, uint32_t y, uint32_t w){ return x * w + y; }
// 线性解码 std::tuple<uint32_t, uint32_t> linear_decode(uint32_t v, uint32_t w){ uint32_t x = v / w; uint32_t y = v % w; return {x, y}; }
// Morton编码:交织x和y的位 uint32_tmorton_encode(uint32_t x, uint32_t y){ uint32_t z = 0; for (int i = 0; i < 16; ++i) { // 假设32位,处理16位 z |= (x & (1u << i)) << i; z |= (y & (1u << i)) << (i + 1); } return z; }
// Morton解码:分离交织的位 std::tuple<uint32_t, uint32_t> morton_decode(uint32_t z){ uint32_t x = 0, y = 0; for (int i = 0; i < 16; ++i) { x |= (z & (1u << (2 * i))) >> i; y |= (z & (1u << (2 * i + 1))) >> (i + 1); } return {x, y}; }
// Hilbert编码(简化递归实现) uint32_thilbert_encode(uint32_t x, uint32_t y, uint32_t n){ uint32_t d = 0; uint32_t s = n / 2; while (s > 0) { uint32_t rx = (x & s) > 0 ? 1 : 0; uint32_t ry = (y & s) > 0 ? 1 : 0; d += s * s * ((3 * rx) ^ ry); if (ry == 0) { if (rx == 1) { x = n - 1 - x; y = n - 1 - y; } std::swap(x, y); } s /= 2; } return d; }
// Hilbert解码(逆过程,较为复杂,此处省略,实际应用中可查表或使用库)
// 遍历函数:生成顺序 std::vector<std::tuple<uint32_t, uint32_t>> generate_order(uint32_t n, const std::string& type) { std::vector<std::tuple<uint32_t, uint32_t>> points; for (uint32_t i = 0; i < n; ++i) { for (uint32_t j = 0; j < n; ++j) { points.emplace_back(i, j); } } if (type == "morton") { std::sort(points.begin(), points.end(), [](constauto& a, constauto& b) { auto [x1, y1] = a; auto [x2, y2] = b; returnmorton_encode(x1, y1) < morton_encode(x2, y2); }); } elseif (type == "hilbert") { std::sort(points.begin(), points.end(), [n](constauto& a, constauto& b) { auto [x1, y1] = a; auto [x2, y2] = b; returnhilbert_encode(x1, y1, n) < hilbert_encode(x2, y2, n); }); } // linear无需排序 return points; }
intmain(){ uint32_t n = 4; auto linear = generate_order(n, "linear"); auto morton = generate_order(n, "morton"); auto hilbert = generate_order(n, "hilbert"); // 输出示例 std::cout << "Linear order:\n"; for (auto [x, y] : linear) { std::cout << "(" << x << ", " << y << ") "; } std::cout << "\n"; // 类似输出morton和hilbert return0; }